takumiです。
前回、「顔認証システムを作りたい!」という話をしました。
今回は、そのために何をしなければいけないのか、
ざっくり「タスク分解」してみました。
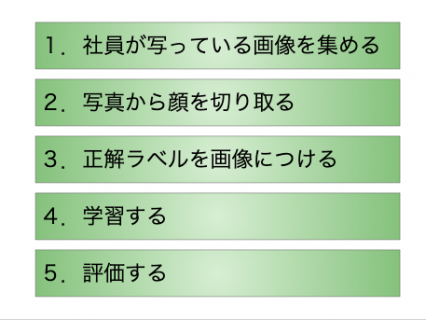
その結果、大きく次の5つの工程になります。
順番に説明します。
1.社員が写っている画像を集める
まず何よりもデータ集めです。
データがないと何も始まりません。
これまでイベントがあるごとに、
撮影係の人が写真を撮ってくれていたと思います。
その写真を使って、顔認証するための元データである、
社員の「顔」をたくさん集めます。
2.写真から顔を切り取る
まず、社員の写っている写真を集めます。
その中に、複数の社員が写っている画像があったとします。
例えばここから、「takumi」だけを学習したいとします。
が、この画像に「takumi」という正解を与えて学習させてしまうと、
この画像にあるすべてのものを学習してしまいます。
つまり「それぞれの顔」とか「後ろにある本」とかもろもろ含めて「takumi」と学習してしまいます。
じゃあどうするか?
ここでは「顔」=「takumi」として学習したいので、
この画像から「顔のみ」切り取る必要があり、顔だけの画像を用意する必要があります。
3.正解ラベルを画像につける
「画像」から「顔」を切り取ることができた、とします。
すると次にこの「顔画像」に、ラベルをつけないといけません。
前々回、「手書き文字分類」をしました。
このときは手書き文字の「画像」に、正解のラベルがついていました。
深層学習では、「画像」と「正解」をペアで学習します。
ただ画像だけ与えても、それが「何なのか」を学習してはくれません。
なので、これと同じように、顔画像に「ラベル」をつける必要があります。
ここまでやってようやく、学習用のデータの完成です。
4.学習する
データができたので、今度はこれを深層学習モデルに
インプットとして渡して、学習します。
ここでようやく、GPUの出番です。
5.評価
最後に、学習結果について評価します。
どれくらい正確に、画像から「誰なのか」を当てることができるのか
また、どれくらい間違えているのかを、数値としてここで明らかにします。
以上が、大まかな流れです。
あとはこれを一通りやったあとに、どうやったらもっと精度をあげられるのか、
いろいろ工夫していく、というような感じになりそうです。
次回は、工程1の「社員の写真を集める」について一回飛ばして、
画像から顔のみ「自動的に」切り取る方法について紹介したいと思います。